June was the month Melaya moved from a broad agent builder into a governed execution platform: one place to design multi-agent workflows, control cost and quality, run locally or in the cloud, connect agents to real systems, and route decisions into a high-performance Rust execution layer.
Executive summary
Melaya entered June with substantial technical breadth. The month’s work was about turning that breadth into a platform an operator can understand, measure, and trust.
The product now combines four connected layers:
- Build: a visual studio for composing agents, crews, tools, context, memory, models, approval gates, and execution policy.
- Govern: deterministic-first evaluations, typed failure reasons, cost attribution, spend caps, human approval, dry-run modes, safety watchers, traces, and kill controls.
- Execute: cloud and local runners for general workflows, plus a normalized Rust engine for market data, backtesting, paper execution, and regulated-path live execution.
- Distribute: 1,366 tools, 110 agent personas across 16 crews, 21 AI providers, nine public SDK languages, five product languages, 15 use-case entry points, and an evidence-backed benchmark surface.
June also clarified the company strategy. Melaya will not treat consequential AI actions as a chatbot feature. The platform is being built around explicit scopes, measurable quality, bounded spend, auditable runs, and human or deterministic controls at the point of action. In trading, hosted consumer live execution remains deliberately gated until Melaya has an appropriate compliant route; paper trading, research, monitoring, backtesting, and local or partner-led paths continue to advance.
June at a glance
| Area | June position | Why it matters |
|---|---|---|
| Engineering activity | 570 June commits; 1,178 files touched | High shipping velocity across product, runtime, engine, integrations, localization, and distribution. These figures include generated catalog/localization artifacts and are activity indicators, not traction metrics. |
| Tool ecosystem | 1,366 catalogued tools | Agents can move beyond text generation into operational systems, data sources, communications, ERP, finance, research, and execution. |
| Agent system | 110 personas across 16 prebuilt crews | Reusable operating roles and team structures reduce the distance from blank canvas to a working workflow. |
| Model ecosystem | 21 AI providers | Operators can route work by capability, privacy, cost, and latency instead of being locked to one model vendor. |
| Model intelligence | 108 static catalog models; 94 with benchmark scores in the current audit | Cost/performance selection is becoming measurable. Remaining static gaps and dynamically discovered live-only model IDs are now treated as separate coverage classes. |
| Developer surface | 9 SDK languages | TypeScript, Python, Go, Rust, Java, Kotlin, C#, Ruby, and PHP expose a consistent normalized API. |
| International reach | 5 languages | English, French, Simplified Chinese, Spanish, and Brazilian Portuguese span public pages, product UI, server messages, tools, and agent personas. |
| Market infrastructure | 70+ normalized venues exposed through the SDK surface | A common interface reduces venue-specific integration cost for data, backtests, paper workflows, and eligible execution paths. |
| Public proof | 5 benchmark surfaces plus reproducible harnesses | Performance claims can be inspected and rerun rather than accepted as marketing copy. |
| Demand discovery | Multiple active B2B, ecosystem, and investor conversations | The commercial focus is shifting from feature breadth toward pilots, distribution, and a compliant path to scale. |
What is available now
The most important June release boundary is simple: Melaya is publicly usable as self-directed agent software, but it is not presenting hosted consumer live trading as an available product.
| Surface | Position at 30 June 2026 |
|---|---|
| Public product and evidence | The website, product pages, use cases, documentation, benchmark datasets, tool/provider/persona catalogs, and public SDK repository are live and inspectable. |
| Agent workflows | Users can build workflows for research, operations, reporting, outreach, local or cloud execution, tool use, RAG, artifacts, evaluation, and human-approved actions, subject to their configured connectors and models. |
| Financial workflows | Paper trading, dry-run crews, backtesting, strategy research, market data, and read-only account or market monitoring are the public execution posture. |
| Hosted consumer live orders | Gated before private credentials or order routing are reached. The interface fails closed and the server gate covers strategy, direct CEX, and prediction-market write paths. |
| Live-execution path | Local-direct execution or a licensed/regulated partner path, followed by jurisdiction-specific rollout where appropriate. |
1. Platform: from workflow canvas to operating system
Agent Builder
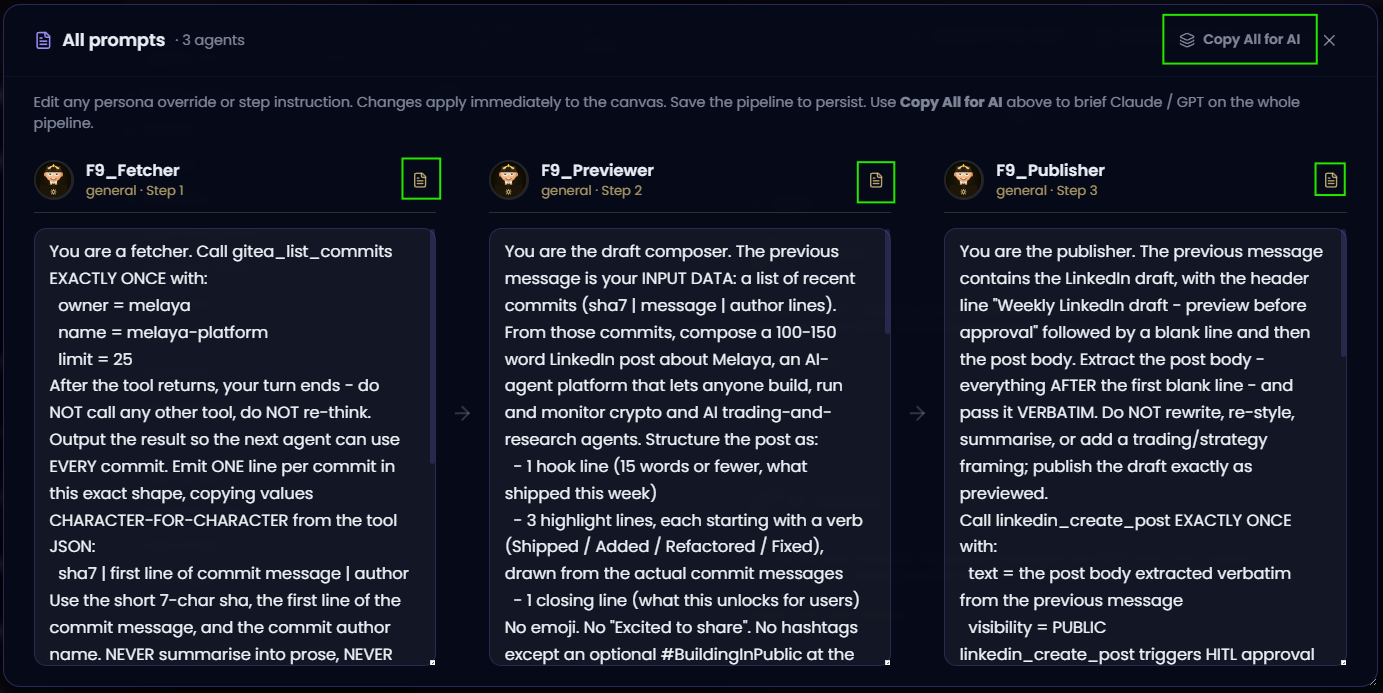
The Agentic Framework and its Agent Builder continued to become the central cockpit for the platform. June improved the parts that matter when a workflow moves beyond a demo:
- Per-agent instructions, model selection, tool scope, context, RAG, and quality-loop policy.
- Parallel and sequential execution paths with clearer code generation and preview.
- Local and cloud launch paths, with local-tier guidance and provider-connection checks.
- File outputs routed consistently for generated spreadsheets, documents, images, and other artifacts.
- Search, filtering, templates, light-mode improvements, and more reliable panel behavior across the builder.
- Write/read capability metadata so consequential tools can be governed differently from retrieval tools.
- Pipeline memory visualization and stronger history, trace, and evaluation navigation.
The product direction is intentional: a user should be able to see not only what an agent is instructed to do, but also which model it uses, which systems it may touch, which data it can retrieve, how much it may spend, what quality bar it must pass, and where a human must intervene.
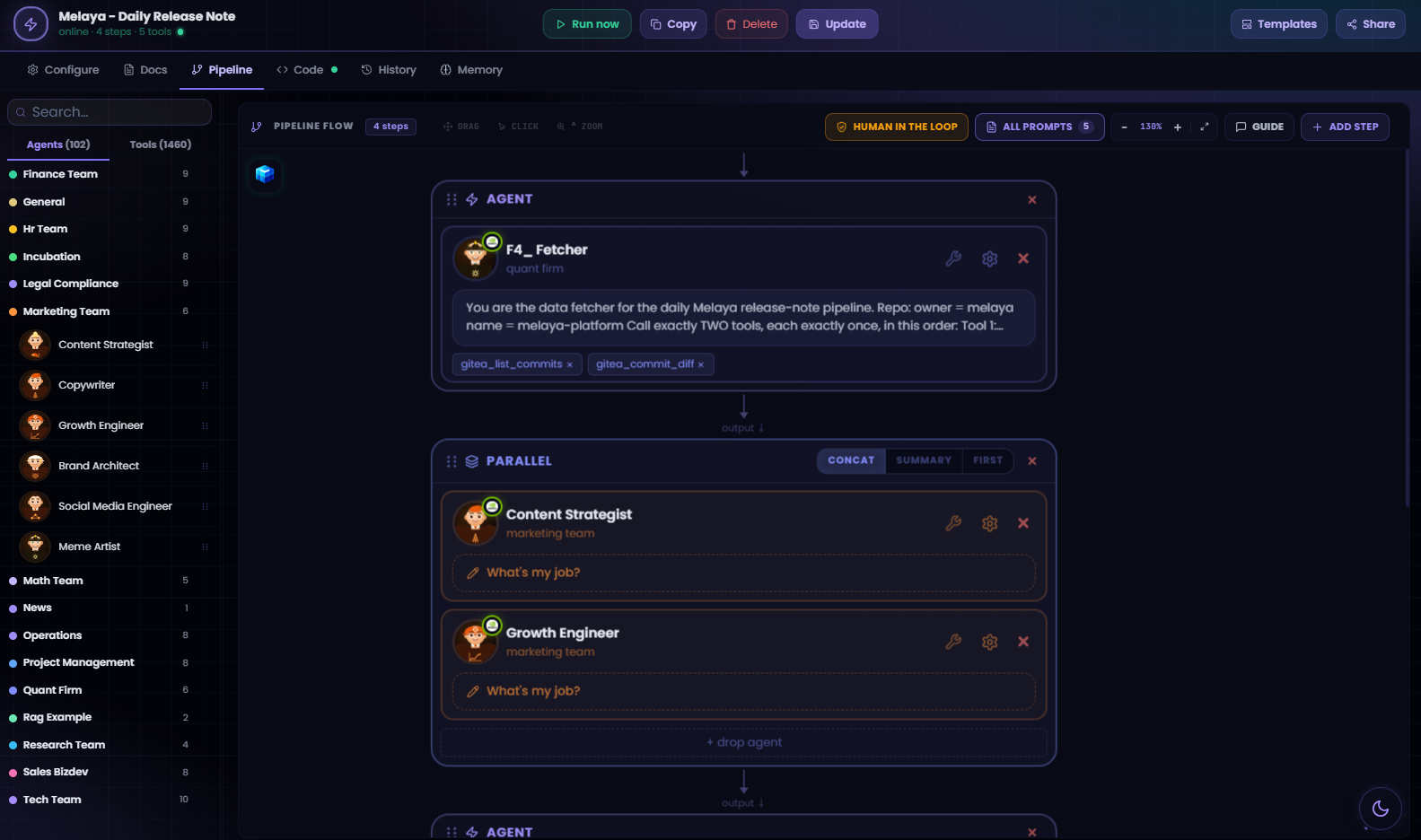
Model routing and cost/performance intelligence
June introduced interactive model cost-versus-performance exploration in 2D, 3D, and an initial 4D view. The goal is not a decorative model leaderboard. It is a routing surface for choosing the right model per agent and per task.
The model catalog brings together:
- Input and output economics.
- Benchmark performance across available dimensions.
- Latency or generation-speed evidence where available.
- Provider availability and live model discovery.
- Pareto-frontier views that expose models offering non-dominated trade-offs.
- A coverage gate that identifies catalog models missing cost or benchmark evidence.
A post-close audit made an important distinction: the interface’s former “unscored” total mixed genuinely unscored catalog entries with extra model IDs returned dynamically by provider APIs. In the current catalog, 94 of 108 static models are scored and 14 are genuinely missing a static score; live-only IDs are a separate, more volatile coverage set. That separation makes the metric actionable and prevents provider aliases or newly listed models from looking like failures in the curated catalog.
Local and cloud execution
Melaya supports both hosted convenience and local control. June strengthened the local runner, cloud endpoints, runtime dependencies, preflight behavior, and provider configuration flow. The public entry point for implementation guidance is the Melaya documentation.
This dual execution model serves three practical needs:
- Privacy: sensitive context and local models can remain within the operator’s environment.
- Capability: local-tier tools and private infrastructure can participate in the same visual workflow model.
- Governance: regulated or consequential execution can be routed through an architecture appropriate to the operator and jurisdiction, rather than forced through a single hosted path.
AI-assisted creation and validation
June strengthened the path from idea to executable workflow. Users can start manually, ask AI to build a pipeline, or begin from a template; inspect backend-generated code in the builder; and move between visual configuration and code-level review without treating generation as a black box.
The same approach now extends into prompt and strategy work:
- “Copy for AI” actions make prompts easy to review with an external coding assistant or CLI.
- Generated pipeline code can be previewed before execution.
- Custom Rhai strategies receive engine-backed validation before launch.
- AI-assisted backtest optimization can propose parameter changes while keeping the resulting values explicit.
- Tool-less agents, parallel branches, and loop-enabled agents now generate against clearer runtime contracts.
For users, this reduces setup and debugging time. For partners, it creates a more inspectable implementation surface than opaque no-code generation. For Melaya, it improves self-serve activation without removing expert control.
2. Agent runtime: quality loops that do not grade their own homework
June’s most important agent-runtime work was the move from “the run completed” to “the output met a defined bar.”
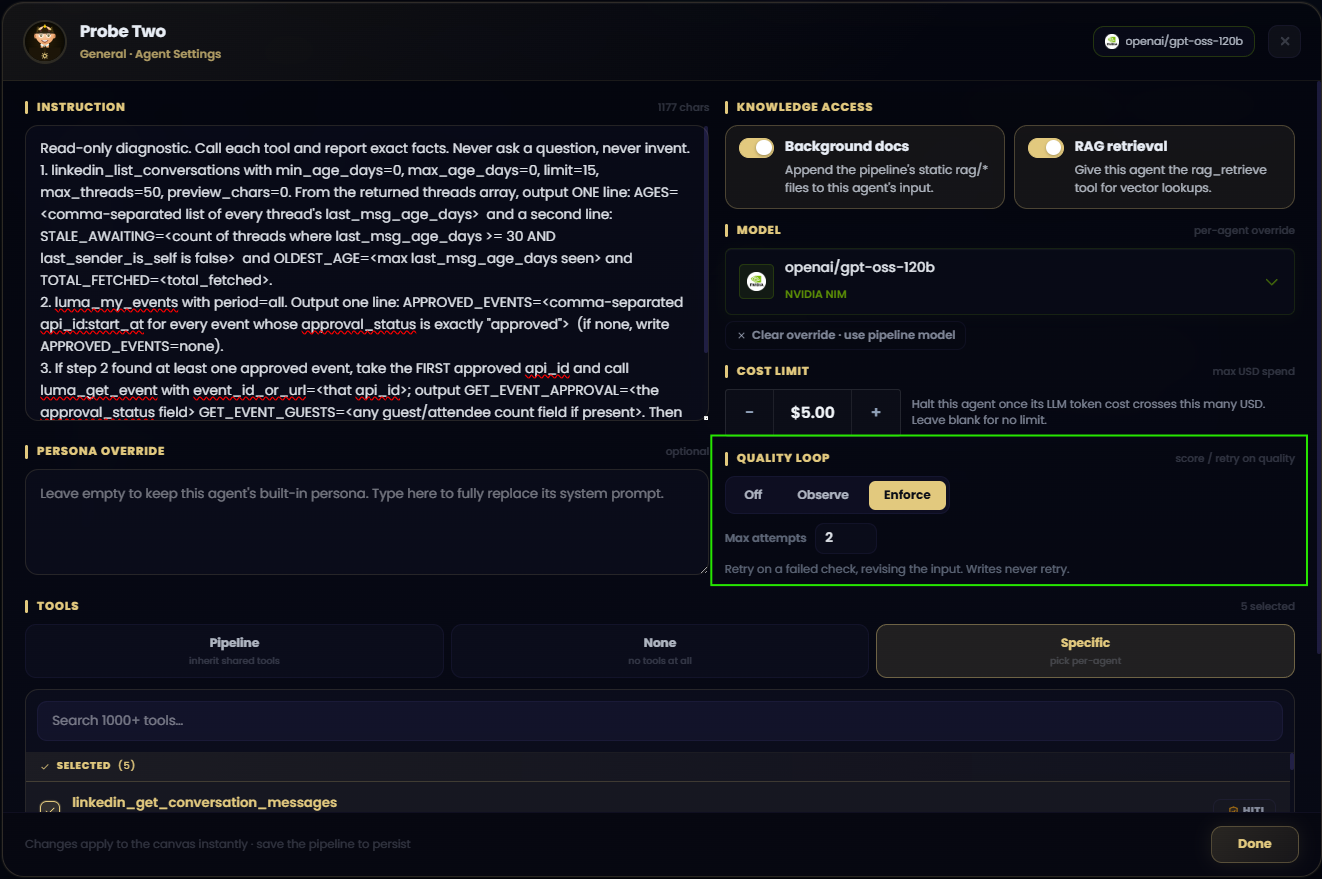
Deterministic-first evaluation
Each agent step can now be checked using deterministic conditions before any model-based judge is consulted. Checks include whether output is empty, whether JSON is valid, whether required sections exist, whether a tool actually succeeded, and whether claims are grounded in retrieved evidence.
Every verdict carries a typed reason and score. This matters because “failed” is not an operational diagnosis; “missing required sections,” “invalid JSON,” or “ungrounded claim” tells an operator which prompt, tool, or policy to change.
Three operator-controlled modes
- Off: preserve previous execution behavior.
- Observe: score and record quality without changing the run.
- Enforce: retry eligible steps or escalate when the threshold is not met.
The policy is configured per agent. A research step can be strict about citations while a creative ideation step remains permissive.
Consequence-aware retries
Melaya does not automatically repeat a consequential action simply because an evaluation failed. Read-only and idempotent work can be corrected and retried; an action such as placing an order or sending a message must not be duplicated silently. Those cases escalate to an operator.
This is a core architectural principle: a quality loop is not allowed to become an unbounded action loop.
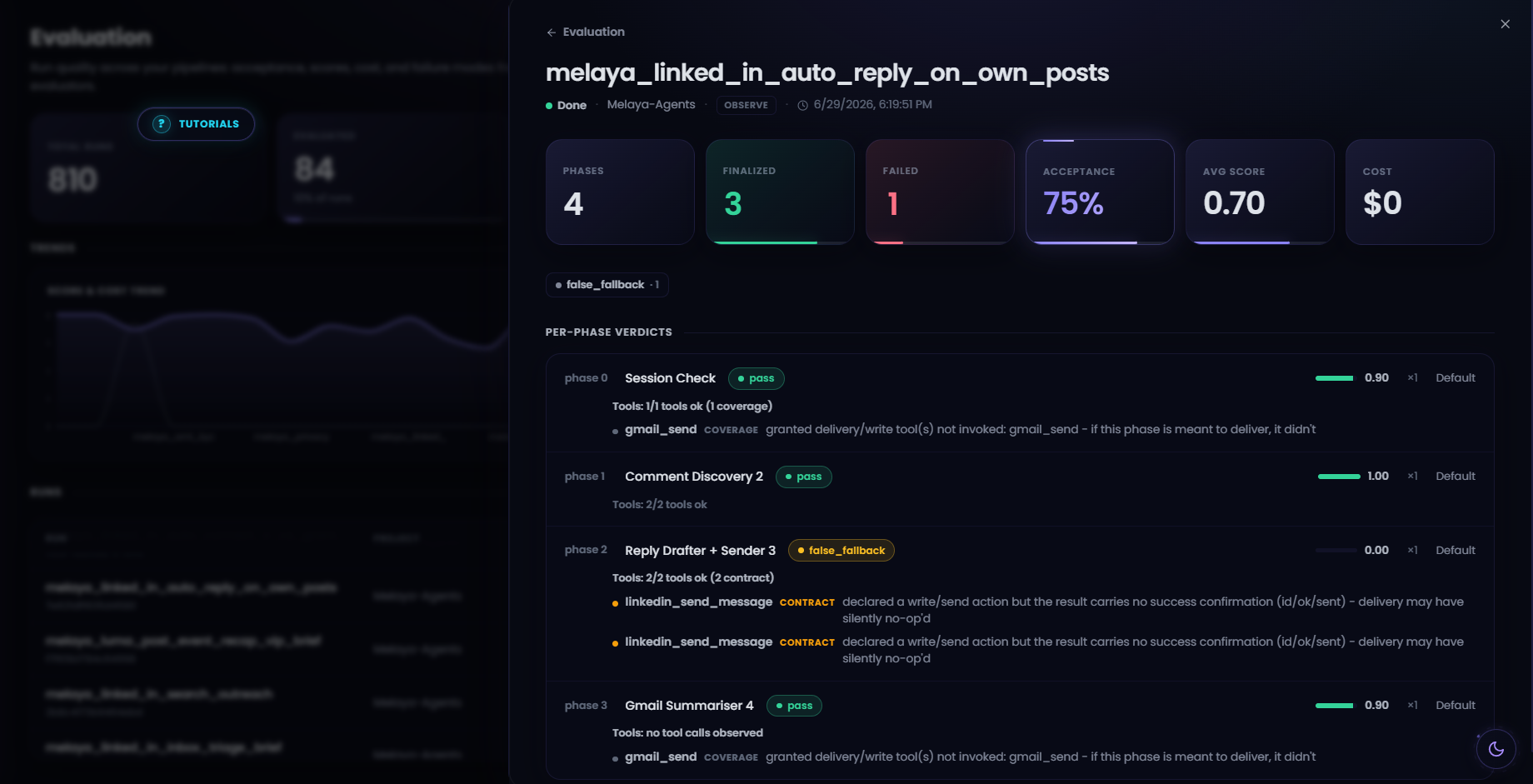
Evaluation control room
The evaluation and trace surfaces now expose:
- Acceptance rate, average score, run count, and common failure modes.
- Per-phase and per-agent verdicts.
- Retry history and typed failure reasons.
- Weakest-agent identification.
- Cost per accepted result.
- Model- and provider-level splits in both currency and tokens.
- Tenant-scoped queries so one organization cannot inspect another’s evaluations or traces.
The runtime work was backed by dedicated tests, including behavior checks showing that the generated execution path remains byte-identical when the loop is disabled.
3. Cost governance and observability
Cost controls moved from estimation toward enforcement.
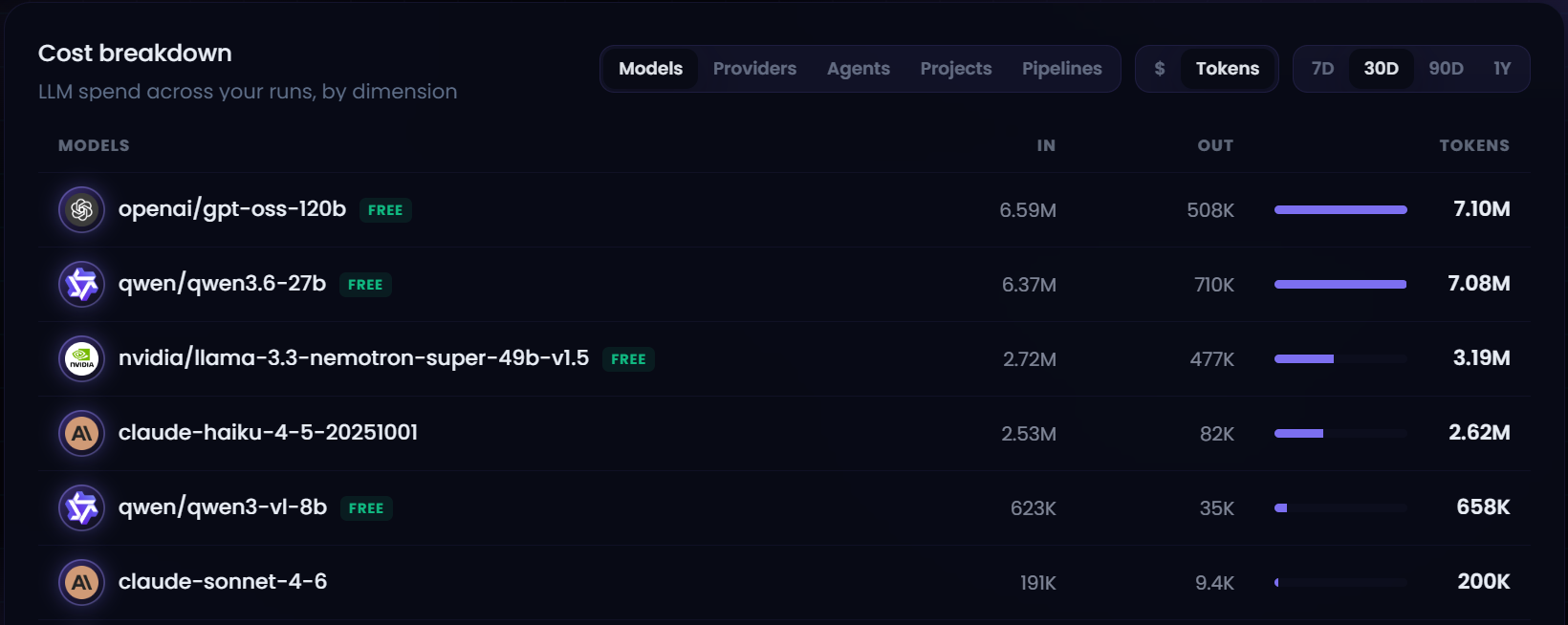
June added or hardened:
- Provider-aware token pricing and per-model attribution.
- Per-agent and per-pipeline budgets.
- Cloud spill-budget enforcement that can stop a multi-agent run before overspend.
- Cost views by provider, model, dollars, and tokens.
- Cost per accepted output rather than cost per attempted run alone.
- Time filtering, project filtering, trace partitioning, and persistent evaluation history.
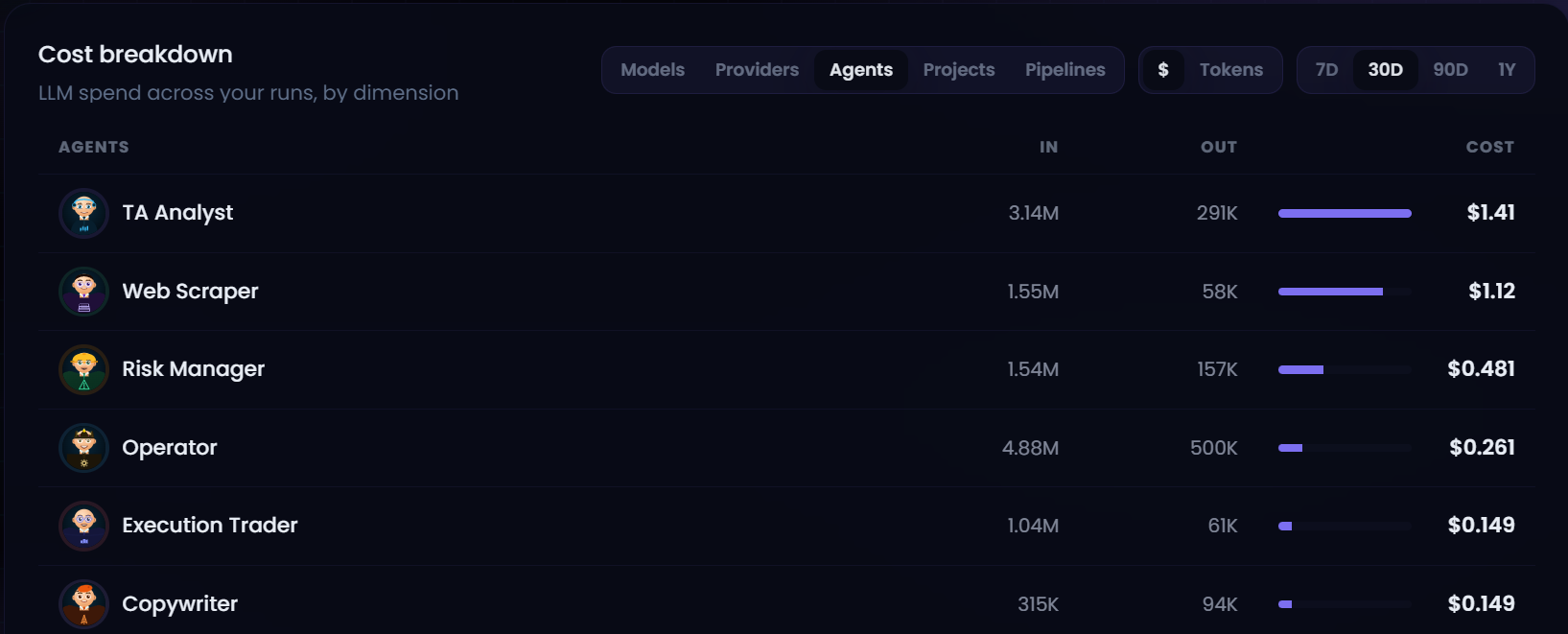
The operating metric Melaya is moving toward is not “tokens consumed.” It is cost per accepted result under a defined quality policy. That aligns model routing, prompt design, tool reliability, and retry behavior around an outcome an operator can evaluate.
4. Memory and RAG
June expanded retrieval beyond a generic vector-search toggle.
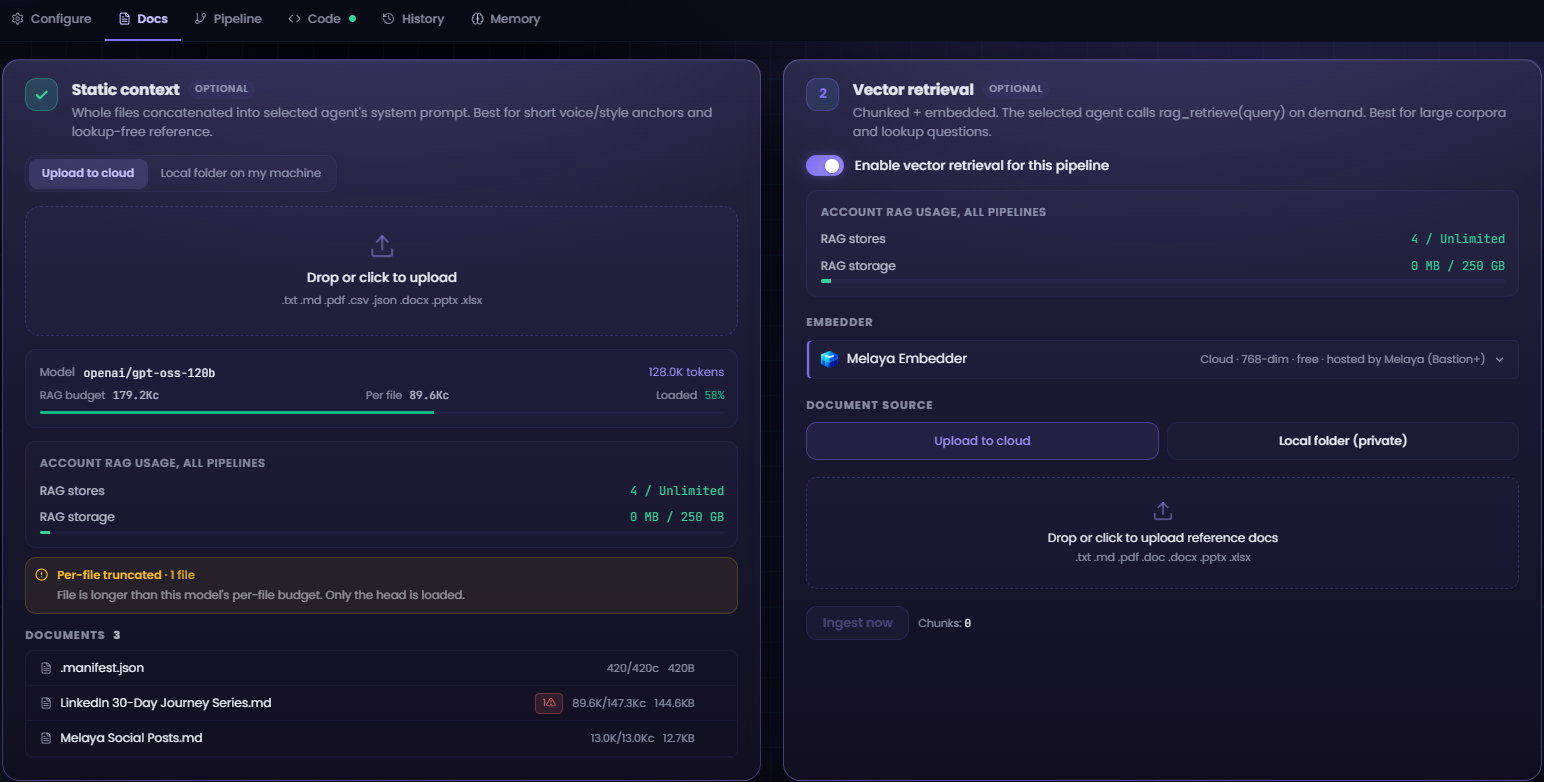
Mode B: local static context
Operators can attach a local folder as static context. The content stays local and does not need to enter the hosted product path.
Mode C: pull-based ingestion
Pipelines can pull and ingest content using a local Melaya AI/Ollama embedding path. The implementation includes:
- Sentence-aware chunking.
- Packing into retrieval windows rather than arbitrary fixed cuts.
- Parallel ingestion.
- Tenant ownership in the vector store.
- Docker and cloud persistence fixes.
- Cloud endpoints to retrieve stored pipeline memory.
The memory graph added at month-end makes retained context visible per pipeline. The strategic value is continuity across runs without making memory an invisible, ungoverned side channel.
5. Rust engine and market infrastructure
The Rust trading engine remains Melaya’s high-performance execution and normalization layer. June’s work focused on breadth, strategy lifecycle, and safety rather than a single latency headline.
Venue and market coverage
Notable June work included:
- End-to-end Bitget Futures support, including positions, protective orders, trailing stops, cancellation, mark-price updates, and position-mode handling.
- BingX Spot and Futures coverage across balances, leverage, trades, liquidation data, and conditional-order workflows.
- OKX swap wiring and continued exchange-adapter hardening.
- Normalized lot-size handling and venue-specific order constraints.
- Open-order recovery after backend restarts.
- Correct account-owner resolution before private-feed or execution actions.
- Validation of 20 prediction-market tools across Polymarket, Kalshi, Drift, SX Bet, Azuro, and Overtime.
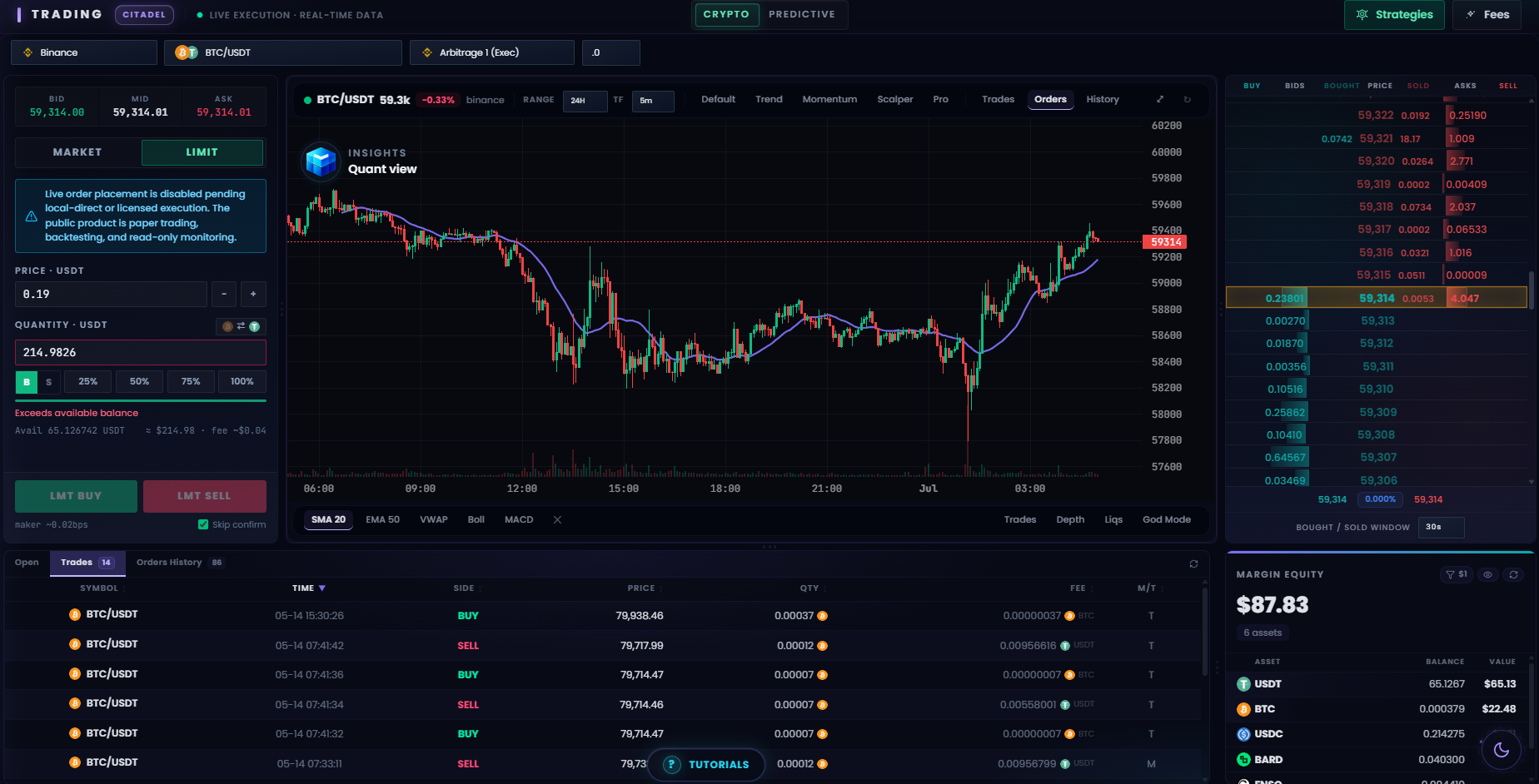
Strategy lifecycle
Custom Rhai strategies can move through validation, parameterization, backtesting, paper or dry-run execution, and eligible live paths using the same engine semantics. Backtests account for venue fills, fees, order type, and realized P&L rather than presenting a disconnected toy simulator.
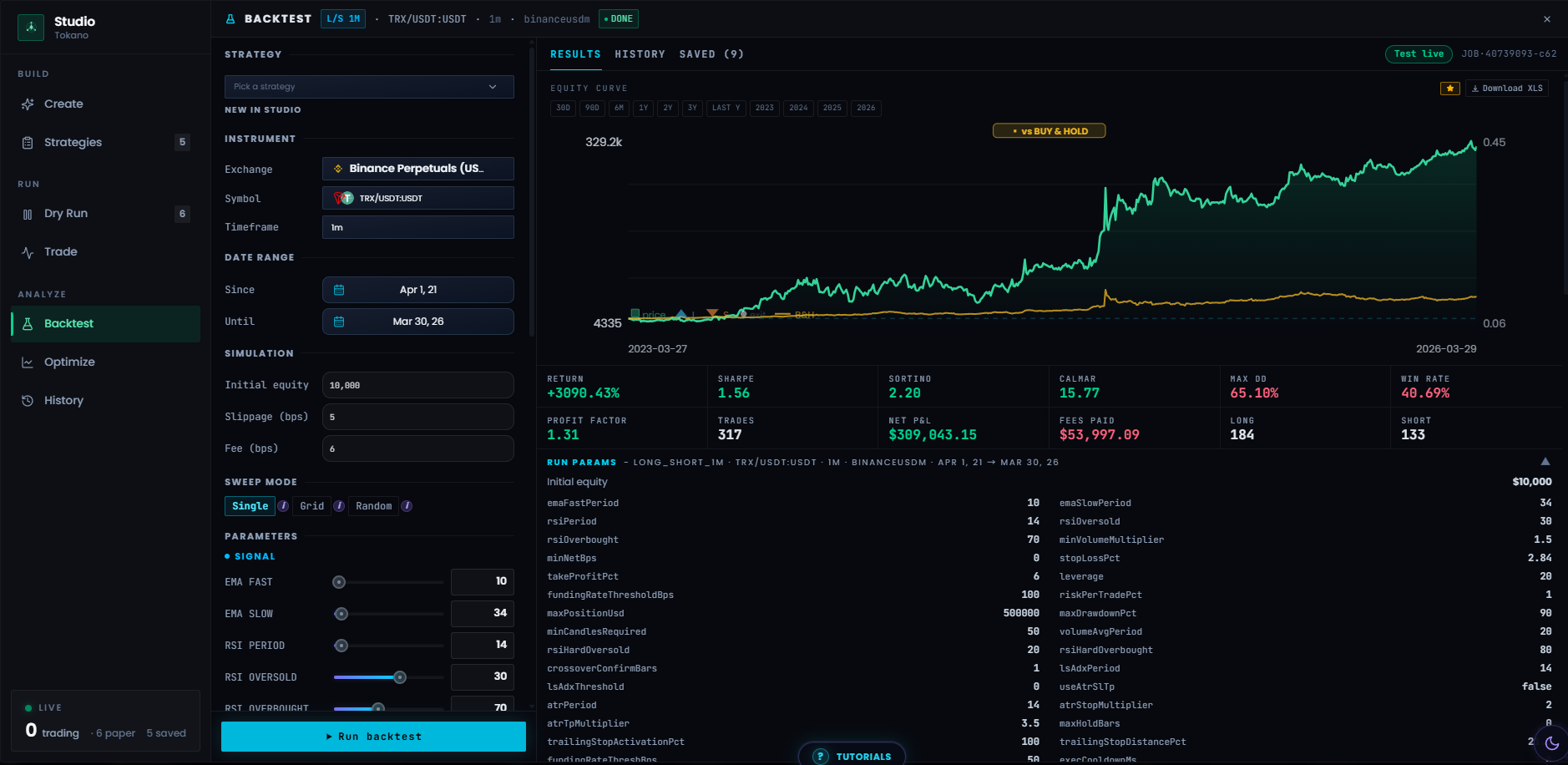
Protective-order behavior was hardened so canceling one child order does not incorrectly remove another, and orphaned stop-loss/take-profit orders are cleaned up when the parent lifecycle requires it.
Prediction markets as a first-class execution domain
Prediction markets moved from fragmented connector aliases to a unified, governed surface. Twenty tools now cover Polymarket, Kalshi, Drift, SX Bet, Azuro, and Overtime through a common venue argument and consistent operation model.
The implementation spans all three execution layers:
- A unified Python tool surface for public reads, authenticated reads, and approval-gated writes such as place, amend, cancel, and cancel-all.
- Generic server dispatch for public and private prediction-market operations.
- Rust-engine handling for venue-specific authentication, signing, and execution semantics.
This matters strategically because it demonstrates that Melaya’s normalization layer is not limited to centralized exchanges. New market structures can inherit the same tool scoping, credential resolution, human approval, paper/research posture, and audit model used elsewhere in the platform. The relevant tools are discoverable through the public tool catalog and align with Melaya’s quant use cases.
Safety watchers for trading crews
Trading crews gained independent processes that observe live feeds and can intervene without waiting for an LLM cycle:
- Drawdown Sentinel: blocks pending actions when configured equity or daily-loss limits are breached.
- Macro Blackout: prevents new entries around specified high-impact events.
- Funding Flip: wakes the crew when a carry assumption changes sign.
- Liquidation Cascade: triggers an additional decision cycle when liquidation activity crosses the configured threshold.
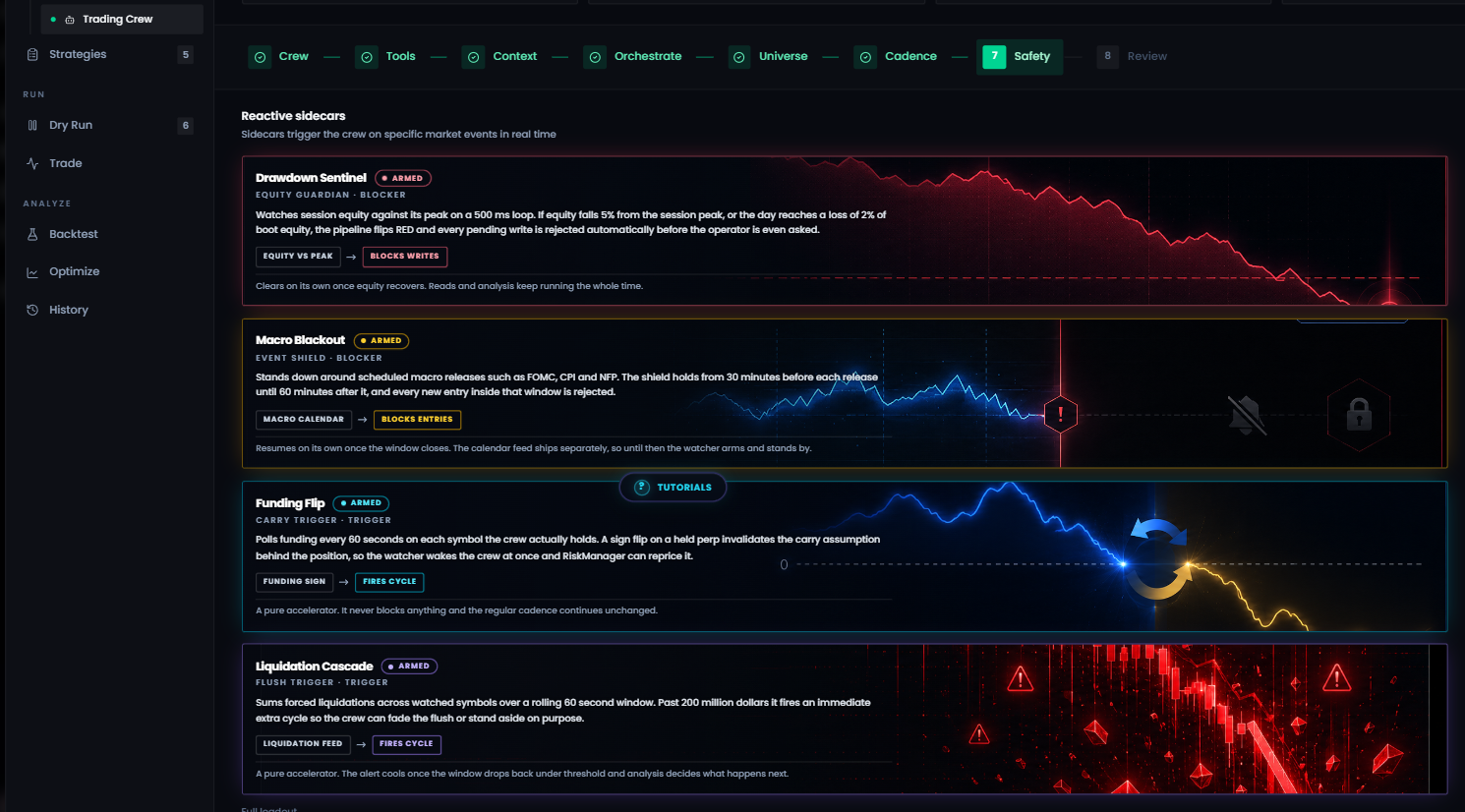
These controls sit beside max-write limits, daily LLM budgets, dry-run execution, pause/resume, and human approval for write tools. The architecture separates model reasoning from the mechanisms that define what the model is never allowed to do.
6. Backend and control plane
June hardened the services connecting the visual builder, agent runtime, integrations, and Rust engine.
Key work included:
- Persistent run, evaluation, trace, cost, and memory records.
- Tenant-scoped access and ownership checks.
- Server-side internationalization for transactional email, API errors, and validation messages.
- WebSocket and event relay improvements for long-running and event-driven workflows.
- More reliable preflight failure handling so failed launches do not remain stuck in a running state.
- Usage monitoring, seat/tier enforcement, and subscription-aware error handling.
- Removal of deprecated prompt and pipeline-level tool-pool paths, reducing duplicated sources of truth.
- Better code generation for tool-less agents and mixed sequential, parallel, and loop execution.
- Cloud endpoints for pipeline memory retrieval and OpenVC pagination support for larger datasets.
The backend direction is a single auditable control plane: configuration, identity, scopes, cost, events, outputs, memory, and evaluations should resolve to the same tenant and run context.
Real-time and recoverable operations
June materially strengthened the platform’s event architecture. Trading and general agent workflows can now combine scheduled cadence with live event triggers, while an event tape and WebSocket relays carry agent messages, tool calls, market updates, approvals, and run-state changes.
The recovery model is deliberately database-backed rather than dependent on an open browser session:
- Agent messages and latest tool activity rehydrate after refresh or reconnect.
- Live WebSocket deltas overlay persisted history instead of replacing it.
- Open orders and relevant exchange state can be recovered after backend restart.
- Failed preflight launches terminate cleanly rather than remaining indefinitely “running.”
- Multi-cycle crews preserve run identity, pipeline context, and operator-visible history across cycles.
For enterprise and execution partners, this is a material distinction: the platform is being designed around durable operational state, not a transient chat stream.
Scaling and workload isolation
June shipped the first concrete capacity architecture for cloud agent runs. Instead of assigning the same container footprint to every pipeline, the runner now sizes workloads by what they actually use: light pipelines, retrieval/RAG pipelines, and browser-heavy pipelines receive different memory envelopes.
Contention handling also moved from immediate rejection to bounded queueing:
- Runs enter a FIFO queue when concurrency or memory headroom is temporarily unavailable.
- Slot claims use a shared Redis-backed cluster cap and memory checks preserve operator-defined headroom.
- A timed-out request returns a retryable response and is explicitly recorded as not started; already-running workloads are not interrupted.
- Local-model workflows dispatch to the user’s local runner and do not consume Melaya cloud-run capacity.
- A worker-selection seam can place containers on the least-loaded configured Docker worker while retaining local fallback and consistent lifecycle control.
The current queue design is intentionally honest about its boundary: the waiter list is correct for the present single control-plane replica, while multi-replica queue coordination remains a future Redis-backed step. The important June outcome is that scaling is now an explicit, measurable execution design rather than an assumption hidden behind pricing tiers.
Usage metering, entitlements, and SaaS readiness
June established more of the commercial control plane required to operate Melaya as a multi-tenant product:
- User and administrator usage monitoring.
- Tier and capability presentation across pricing, subscription, and upgrade surfaces.
- Selected enforced gates, including API-key self-service eligibility and existing strategy/CEX limits.
- A separate fail-closed live-execution gate that preserves paper, dry-run, research, and monitoring workflows.
- Subscription-aware errors and clearer upgrade guidance at the point of use.
- Provider-aware cost tracking alongside per-agent and per-pipeline limits.
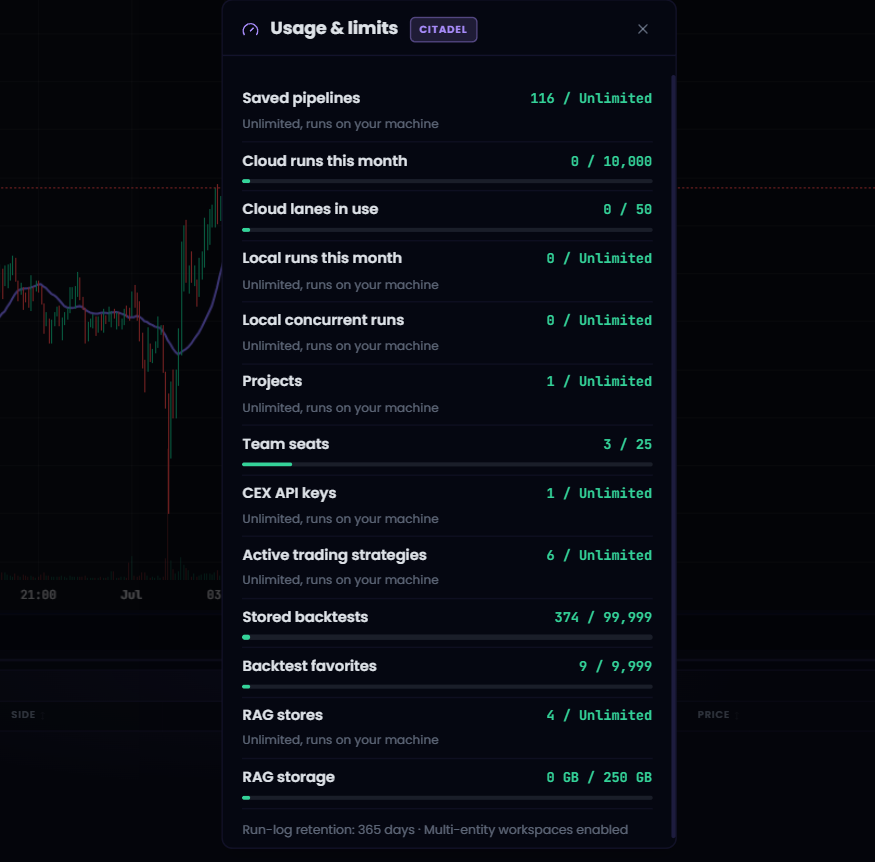
This is a foundation rather than a claim of completed entitlement enforcement. Project, saved-pipeline, monthly-run, tool-count, RAG-storage, and team-seat limits were represented in packaging during June but were not all enforced at runtime; multi-user team seats were not yet a complete product capability. Making that distinction public protects the credibility of future pricing and enterprise commitments.
7. AI providers, tools, and integrations
Model-provider expansion
Public AI-provider coverage provides the current inspectable provider catalog.
June added or completed work across Gemini, Qwen, Grok, Mistral, NVIDIA, Groq, Cerebras, DeepSeek, SambaNova, Upstage, Reka, MiniMax, OpenRouter, Gonka, and the Moonshot/Kimi family, bringing the catalog to 21 providers.

Provider diversity is not an end in itself. It enables routing by:
- Capability and benchmark evidence.
- Price and budget.
- Latency or throughput.
- Data-residency and local-execution requirements.
- Availability, credits, and operational fallback.
Operational tool surface
The public tool catalog reached 1,366 tools. June highlights included:
- 150+ Odoo tools spanning CRM, sales, inventory, finance, and related ERP workflows.
- LinkedIn workflow expansion and hardening.
- Discord plus Instagram, Facebook, and X integrations.
- Web search, RSS, browser, Google Search Console, Luma, Twilio/WhatsApp, email, and communication-tool cleanup.
- OpenVC connection and pagination improvements.
- Prediction-market tooling across six ecosystems.
Tool capability metadata now makes it easier to distinguish read operations from writes and apply approvals or policy accordingly.
Research, browser, and communications workflows
June broadened Melaya’s general-purpose automation surface beyond trading and ERP. Research workflows can combine RSS-first discovery, web search, deep-page retrieval, browser execution, liveness checks, and local RAG. Communication workflows expanded across LinkedIn, Discord, Instagram, Facebook, X, email, WhatsApp, Luma, and webhooks.
The value is in composition rather than connector count: an agent crew can discover a source, verify it, ground an output, generate an artifact, request approval, and publish or send through a scoped write tool. The research, marketing, and sales use cases make those paths visible to non-trading buyers.
Local content pipeline
A local-first content workflow demonstrated the platform outside trading: RSS and web retrieval feed five parallel agents, which produce a meme using local templates and Pillow rather than a third-party image-generation API. The output is a concrete example of Melaya’s general pattern—retrieve, coordinate, evaluate, produce an artifact—running within a controlled environment.
8. SDK and developer platform
June opened the steering wheel while keeping the engine and normalization layer protected.
The public melaya-labs/melaya developer surface provides SDKs in nine languages. The table links registries where a public package page was verifiable on 1 July 2026 and links the public source package everywhere else.
| Language | Public package or source evidence |
|---|---|
| TypeScript / JavaScript | @melaya/sdk on npm · source |
| Python | melaya on PyPI · source |
| Go | melaya-go on pkg.go.dev · source |
| Rust | public Rust SDK source |
| Java | public Java SDK source (org.melaya:melaya-sdk) |
| Kotlin | public Kotlin SDK source (org.melaya:melaya-sdk-kotlin) |
| C# / .NET | public C# SDK source (Melaya) |
| Ruby | melaya on RubyGems · source |
| PHP | melaya/sdk on Packagist · source |
Each SDK targets the same normalized concepts: market data, public and private streams, account state, paper orders, eligible live-plane operations, backtesting, and strategy events. The published work reports end-to-end checks across the language implementations rather than treating generated client code as sufficient proof.
This strategy expands distribution without commoditizing the core moat. Developers receive a consistent interface; Melaya retains the venue normalization, routing, governance, and engine implementation behind it.
Open developer evidence and release hygiene
The public developer repository includes a top-level implementation guide, runnable examples, a changelog, contribution guidance, a security policy, and Apache-2.0 licensing. This makes the SDK surface reviewable as an operating project rather than a landing-page claim.
9. Benchmarks and evidence
June published five benchmark surfaces through the public benchmark hub:
The reproduction repository includes Rust Criterion workloads and Python framework benchmarks, with pinned runners and a Docker path intended to reduce host variability.
The published engine dataset records a 310 ns p50 TickerCache measurement across 89,033 samples on the named Ice Lake-SP environment. This is a workload- and hardware-specific engine measurement—not end-to-end exchange, network, agent, or human latency.
The benchmark methodology also deliberately separates the software overhead of entering and leaving a human-approval gate from actual human response time. The internal gate is measured under 100 µs; the human round trip is intentionally described as methodology-only until production telemetry can support a real distribution.
That distinction is important to Melaya’s positioning: benchmark individual layers honestly, publish the harness, and avoid combining incomparable measurements into a single marketing number.
10. Frontend, product experience, and accessibility of the story
June’s frontend work was not limited to visual polish. It reduced the cognitive load of a technically broad product.
Highlights included in the public use-case hub:
- A landing page reduced from eight sections to five focused sections.
- Three plain-language product pillars: Framework, Crew, and Engine.
- 15 use-case pages covering 10 departments and five personas.
- Reworked builder panels, templates, model selection, strategy views, evaluation dashboards, trace views, and memory visualization.
- Stronger light-mode and cross-browser behavior.
- Better onboarding guidance, connection flows, quick-connect behavior, and subscription errors.
- Social sharing and automated video-onboarding work.
The use-case pages are grounded in actual crews, tools, local-model options, scopes, and approval controls. They do not rely on invented customer stories or hypothetical integrations.
11. Internationalization, SEO, and distribution
Melaya became a genuinely multilingual product in June, not an English application behind a translation widget.
Five-language product
English, French, Simplified Chinese, Spanish, and Brazilian Portuguese now extend across:
- 145 Public marketing routes.
- Product UI namespaces.
- Tool descriptions keyed by tool ID.
- 110 personas across 16 crews.
- Server validation and API errors.
- Transactional email.
- Agent persona prompts and language propagation at runtime.
- Language-specific brand voice and translation-review rules.
Search and machine-readable discovery
June’s SEO work included:
- Per-route metadata.
- JSON-LD for structured search results.
- IndexNow submission.
llms.txtfor AI-crawler context.- Non-JavaScript prerendering where needed.
- Language-prefixed public routes.
hreflangand language-specific sitemaps.- Use-case architecture aimed at department- and persona-level search intent.
The distribution thesis is broader than conventional SEO: each language and use case should be independently understandable by a human buyer, a search engine, and an AI answer engine.
The resulting machine-readable surfaces can be inspected directly through llms.txt, the XML sitemap, and the generated catalog-count feed. The five localized route families are visible from the English, French, Simplified Chinese, Spanish, and Portuguese use-case hubs.
12. Security, governance, and regulatory posture
June reinforced a clear operating principle: technical readiness is not legal authorization.
Governance already in the product
- Human approval for consequential write tools.
- Dry-run and paper modes.
- Per-cycle write caps and per-day or per-pipeline spend caps.
- Independent safety watchers.
- Local execution options.
- Tenant-scoped data and evaluation access.
- Traceable tool calls, evaluations, and costs.
- Consequence-aware retry rules.
- Kill, pause, and resume controls.
Credential and tenant isolation
June hardened identity resolution at the paths where mistakes would be most consequential. Private WebSocket feeds now resolve the authenticated API-key owner before private balances, orders, or credentials are accessed. Connector credentials are scoped to the owning tenant and run context, and tenant filters also apply to evaluations, traces, memory, and retrieved pipeline state.
Local execution and local-folder RAG add a separate privacy boundary for workloads that should not send source documents or credentials through a hosted path. Together, these controls make identity, execution scope, and data location explicit parts of the workflow architecture.
Hosted live-trading gate
Melaya deliberately gated hosted consumer live trading while the appropriate legal and operational framework is established. Research, monitoring, backtesting, paper trading, and product development continue. Candidate paths include local-direct execution, licensed partners, broker/VASP partnerships, and jurisdiction-specific rollout.
For investors and partners, this is not a reduction in ambition. It is evidence that Melaya treats the compliance perimeter as part of the product architecture rather than a disclaimer added after deployment.
The public SDK repository also exposes a security reporting policy and issue tracker, providing external routes for responsible disclosure and reproducible implementation feedback.
13. Go-to-market and company development
Positioning and onboarding
June simplified the company story to: build AI agents for any job, and let some of them trade. The product and website now give founders, operators, departments, traders, and developers a concrete entry point rather than asking them to decode an agent-platform category.
The beta funnel is being supported by clearer use-case pages, local/cloud onboarding, provider setup guidance, an automated video pipeline, the public SDKs, and reproducible benchmarks.
Melaya was also accepted into the Founders for Founders program, adding a structured peer and operator feedback environment around a solo-founder company.
Founder-market fit and AI-native operating leverage
Melaya’s trading wedge is grounded in the founder’s operating background rather than selected only because it is a large market. Antoine Roche has worked across BNP Paribas CIB front-office systems, HFT and market-making interfaces, market-data quality, treasury and reporting automation, and DeFi execution products. That history explains the product’s bias toward state recovery, approvals, observable operations, and explicit failure modes.
June also demonstrated an AI-native company operating model. One founder used AI across engineering, debugging, localization, benchmark generation, documentation, content production, and product review while retaining direct verification against code, logs, datasets, and builds. The 570-commit month is not presented as customer traction; it is evidence of unusually high product-development leverage across Rust, Python, TypeScript, infrastructure, design, and distribution.
The operating risk is equally clear: breadth and verification load can concentrate around one person. June’s answer was to turn more of that verification into product and process. Deterministic evaluations, coverage gates, reproducible benchmarks, compile/build checks, public evidence, and explicit regulatory controls. This matters to investors because the next hiring and capital step is not proving that Melaya can be built; it is converting founder-led velocity into repeatable pilots, support, and distribution.
B2B partner pipeline
Active conversations are under way with multiple AI integration and delivery firms, including **Valthena, Beejtech, Jada Squad, Medme, Tecbrix, Reply, Techgropse and more.
The immediate commercial objective is to convert the strongest conversations into scoped pilots where Melaya’s orchestration, local/cloud execution, tool catalog, evaluation, or industry-specific infrastructure creates a measurable implementation advantage.
These are active discussions, not announced contracts or closed partnerships.
Integration and ecosystem pipeline
Melaya is also in active integration or ecosystem discussions with Alibaba Qwen, Gonka AI, Tavily, SnapTrade, and OpenVC.
The strategic fit spans model access, local or decentralized inference, search and retrieval, financial connectivity, and founder/investor workflow automation. Broader relationship status should continue to be described as ongoing discussion until formally agreed.
Fundraising
The company is in active conversations with 10+ investors. This recap does not name individual funds because discussions are ongoing and no financing outcome is being announced.
The fundraising narrative is becoming sharper:
- A technically differentiated execution and normalization layer.
- A governed multi-agent control plane above it.
- An integration and SDK strategy that expands distribution without opening the core engine.
- A credible path across general enterprise workflows and specialized financial infrastructure.
- An explicit compliance strategy for consequential execution.
14. What June proves
1. Melaya is no longer only a builder
The differentiated product is the full operating loop: build, scope, retrieve, run, evaluate, approve, trace, cap, and improve. Many tools can draw an agent graph; fewer can tell an operator which agent failed, why it failed, how much the accepted result cost, which action requires approval, and which deterministic process can stop it.
2. The Rust engine and the general agent platform reinforce each other
Trading forces the platform to solve hard problems early: live events, state recovery, venue normalization, private credentials, deterministic risk, human approval, and consequence-aware retries. Those capabilities improve the general enterprise platform. In return, the broader agent studio, tool catalog, RAG, evaluation, and local execution layers make the engine accessible to more workflows and partners.
3. Model independence is becoming an operating advantage
Twenty-one providers, live discovery, pricing, benchmark coverage, and cost/performance views create the foundation for dynamic routing. The opportunity is not simply to offer a long model dropdown; it is to choose the least expensive model that meets a task’s quality, latency, privacy, and availability requirements, and prove the decision from measured data.
4. Distribution now has multiple surfaces
Melaya can reach operators through the visual product, developers through nine SDKs, implementation partners through a broad connector surface, search demand through localized use cases, and technical buyers through reproducible benchmarks.
5. The company can move quickly without hiding constraints
June paired high shipping velocity with public benchmark methodology, explicit model-coverage gaps, a hosted live-trading gate, and careful language around active discussions. That combination of speed plus visible constraints is the standard required for a platform that intends to let agents act.
15. July priorities
- Convert partner discussions into pilots. Select use cases with a clear owner, measurable outcome, bounded integration surface, and a short path to proof.
- Complete model intelligence. Close remaining static benchmark gaps, resolve aliases, distinguish live-only discovery, deepen tool-calling coverage, and make routing recommendations task-specific rather than globally averaged.
- Operationalize quality economics. Use cost per accepted result, failure types, and retry behavior to improve templates and default model assignments.
- Harden local and cloud runners. Continue reliability, memory, event-stream, artifact, dependency, and recovery work under realistic multi-agent loads.
- Advance the compliant execution path. Evaluate local-direct and licensed-partner structures, document jurisdictional constraints, and keep hosted consumer live trading gated until the path is defensible.
- Drive SDK adoption. Improve examples, package distribution, integration guides, and end-to-end verification across all nine languages.
- Turn multilingual reach into qualified demand. Measure indexing, use-case conversion, beta onboarding, and partner-originated opportunities by language and segment.
- Preserve benchmark credibility. Keep datasets, hardware context, harness versions, and non-comparable layers explicit as coverage grows.
Closing perspective
June did not produce one isolated headline feature. It connected the pieces required for an agent platform to become operational infrastructure.
The frontend now explains and controls more of the system. The backend records and governs it. The agent runtime measures output quality and cost. Memory survives across runs. The Rust engine normalizes high-performance market infrastructure. The SDKs open a developer path. Localization and SEO open new distribution paths. Partner and investor conversations are testing whether those capabilities map to urgent external demand.
The next phase is conversion and proof: fewer broad possibilities, more scoped deployments; fewer model claims, more task-level evidence; fewer conversations, more pilots; and a compliant route for the areas where agents move from recommending actions to executing them.
Evidence and measurement notes
Public evidence index
| Claim area | Public evidence |
|---|---|
| Availability and access | Register · documentation · public SDK repository |
| Product architecture | Agentic Framework · Trading Crew · Trading Engine |
| Developer platform | Public SDK repository · documentation · examples |
| Performance methodology | Benchmark hub · engine harness · framework harness |
| Catalog breadth | Tools · personas · providers · counts feed |
| Use-case distribution | 15-use-case hub |
| Search and AI discovery | llms.txt · sitemap |
| Open-project hygiene | Changelog · security · license |
| Founder context | Antoine Roche · Melaya company page |
Measurement notes
- Git activity was measured over 1–30 June 2026 on the repository history: 570 commits and 1,178 touched files.
- Churn is concentrated in
client/src,melayaAgents,server/src,packages/runner, andrust/melaya-engine; generated translations and catalog files inflate raw addition/deletion counts, so those counts are intentionally omitted from the headline. - Catalog snapshot: 1,366 tools, 110 personas, 16 crews, and 21 AI providers.
- Current model audit: 108 static catalog entries, 94 scored, 14 static score gaps. Dynamically discovered provider-only IDs are not counted as static catalog gaps.
- “70+ venues” describes the normalized developer/API surface documented with the June SDK release; it is not a claim that every venue supports every private operation or order type.
- Engine latency figures are benchmark-specific. They do not include network, venue, model, orchestration, or human latency.
- Partner, ecosystem, and investor names describe active conversations only unless a separate signed announcement exists.
